
Nbody 1.04
Message boards :
News :
Nbody 1.04
Message board moderation
Previous · 1 · 2 · 3 · 4 · 5 · 6 · Next
| Author | Message |
|---|---|
|
Send message Joined: 25 Aug 11 Posts: 2 Credit: 250,474 RAC: 0 |
Thanks, guess I'll have to resort to patience, my favorite character. LOL |
|
Send message Joined: 4 Sep 12 Posts: 219 Credit: 456,474 RAC: 0 |
Just a followup to my previous posts. Actually, on further investigation - sorry, no, it doesn't make sense. Searching for "ktm32.dll", Google finds very little: the top hit is this milkyway thread from April 2012. But it also finds this little bit of milkyway code (again, 10 months old) at github: ktm32Lib = LoadLibrary("KtmW32.dll"); Now, KtmW32.dll does exist (ktm32.dll doesn't) as a perfectly good Microsoft system file on my machine, in both 64-bit (\system32) and 32-bit (\sysWOW64) versions on Win7/64: but dependency walker finds no reference to it in either the current milkyway_nbody_1.04_windows_x86_64__mt.exe application or its matching libgomp and pthread DLLs. I haven't got a MW task running at the moment, because I'm planning a hardware upgrade later today: I'll try one then, and have a more thorough poke around with process explorer. I won't be able to test on XP after all, because I only have XP/32 available here and this build seems to be 64-bit only. |
|
Send message Joined: 7 Jun 08 Posts: 464 Credit: 56,639,936 RAC: 0 |
LOL... I see you've been continuing the sleuthing as well! :-) Yes, I hadn't gotten around to digging into source code yet, but had figured out ktmw32.dll is the file name in the OS. So it appeared to me the spelling in the message string is most likely a typo, but I don't know for sure about that. I agree there is not a whole lot about the DLL's function discussed online outside of the ones you mentioned. However this link: http://www.win7dll.info/ktmw32_dll.html Gave some interesting details about it. Given the static links and other info presented about it, it sure looks like it plays a role in the OS handling CPU task scheduling and other key functions. |
|
Send message Joined: 4 Sep 12 Posts: 219 Credit: 456,474 RAC: 0 |
LOL... I see you've been continuing the sleuthing as well! :-) That would be my guess as well: the LoadLibrary call looks right, but the error message was written by a human being, in a hurry, tired, anxious to get home at the end of the day. It happens. "Could not load Ktm32.dll" exists as a string in the current .exe too - somebody might have a go at that, please - it would help this sort of debugging exercise. I agree there is not a whole lot about the DLL's function discussed online outside of the ones you mentioned. Indeed so. Poked at the .exe file with a Hex editor too, and found this text string: nthreads....BOINC argument for number of threads. No effect if built without OpenMP Also finished my upgrade, and started another N-Body task. You're right: process explorer shows ktmw32.dll in the image list, but I haven't caught it spiking above 12.5% yet. Next step for me: wrap an app_info round the app, and pad it with a fake MT plan_class (so that BOINC keeps the right number of cores free for it), and see what happens. |
|
Send message Joined: 18 Nov 10 Posts: 19 Credit: 182,620,192 RAC: 0 |
On a SECOND system that is working ALMOST. There does seem to be some hyper-dependency on the elements found on the system. It does not work on a pristine system and goes pretty crazy on my working system. I will continue to try do disassemble what you are doing from the outside and see if I can find anything. I have a near pristine Ivy Bridge Core i7. I removed and restored MilkyWay on it with no change in behavior. The Nbody tasks run but 8 of them run in parallel instead of 1 with 8 threads. The files that are found in slot 1 of one of the idled 8 milkyway workloads is: boinc_task_state.xml --- <active_task> <project_master_url>http%3 |
|
Send message Joined: 4 Sep 12 Posts: 219 Credit: 456,474 RAC: 0 |
OK, here's Nbody v1.04 running multi-threaded (3 threads - my choice), with the -nthreads at the end of the command line. 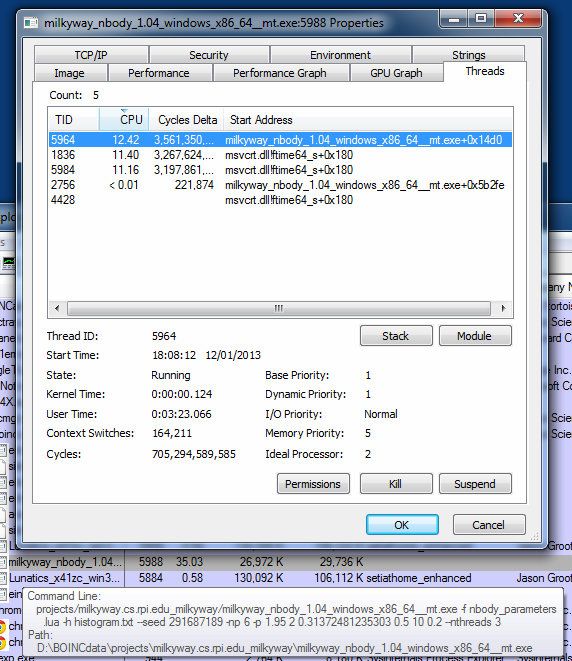 It's task 379807382 - let's see what happens. I can already peek into the slot directory and read this from stderr.txt: Using OpenMP 3 max threads on a system with 8 processors |
|
Send message Joined: 26 Jun 12 Posts: 2 Credit: 7,164,457 RAC: 0 |
I have Workunit 291627243 running on my PC. It's ran 101 hours and says it still has 178 hours to go. However, it is only showing 24% complete. So, I would infer there is another 300 hours to go... The due date is 1/17 which is only 120 hours away. I hate to abort it at this point. Can I get an extension on it? I probably won't run any more of them though. Thanks, Chuck |
|
Send message Joined: 26 Jun 12 Posts: 2 Credit: 7,164,457 RAC: 0 |
Update - The time to completion keeps increasing. I hadn't noticed that before, but in the last ten minutes the completion time has increased almost an hour. I am going to abort it... Losing 101 hours of crunching, but it appears to be a lost cause anyway... Chuck |
 Penguin PenguinSend message Joined: 4 Mar 12 Posts: 45 Credit: 460,346,332 RAC: 0 |
Hello, I run win7 64 bit and was sent a work unit for de_nbody_105 that has been running for 34:00:32 and is at 19.512% complete. The est run time is 2168 hrs. What do I do with this fella?? I'm not a computer wiz in any sense of the imagination, just crunchin' numbers for BOINC. Any suggestions?? I'm guessing it should finish in about 170hrs or a little over 7 days. That is going by that it took approximately 34hrs at 20% and 5 times 34 gives us 170hrs. 100% / 20% gave me that 5. So you should easily make it by the due date. Good luck with the number crunching. |
|
Send message Joined: 7 Jun 08 Posts: 464 Credit: 56,639,936 RAC: 0 |
Update - The time to completion keeps increasing. I hadn't noticed that before, but in the last ten minutes the completion time has increased almost an hour. I am going to abort it... Losing 101 hours of crunching, but it appears to be a lost cause anyway... Agreed. I took a look at the stderr info for the task, and it looks like it would have faulted on exit after completing the run anyway due to the restart problem, regardless of whether it could have made the deadline. |
|
Send message Joined: 7 Jun 08 Posts: 464 Credit: 56,639,936 RAC: 0 |
OK, here's Nbody v1.04 running multi-threaded (3 threads - my choice), with the -nthreads at the end of the command line. Cool, it's completed now. My money is on it validating when the time comes. |
|
Send message Joined: 5 Nov 12 Posts: 3 Credit: 6,378,981 RAC: 0 |
I also have a nutcase called WU294015641 Has 30% done after 15hrs and got 748hrs to complete.. Uses N-Body 1.04 but the name of the WU states "ps_nbody_105_1356215205_223952", 1.05? |
|
Send message Joined: 4 Sep 12 Posts: 219 Credit: 456,474 RAC: 0 |
I see (application details for host 465695) that I've got 14 validated tasks since installing my app_info.xml, and 14 "completed" tasks as well - which implies that this project isn't using the "runtime outlier" protection mechanism described in changeset d8f13a3. That explains why my host was allowed to build up such an insane APR (now 1710.5) while running the stock version of this application. The anonymous platform record shows a much more reasonable 91.2 APR: I'll plug that into my app_info, and see if I can finally get some reasonable runtime estimates. Edit - that's re-estimated an existing orphan_real to 5 minutes, and fetched me three more estimated at 30 seconds. It's also fetched me a _105_ estimated at 24 hours. Again, we'll see. |
|
Send message Joined: 7 Jun 08 Posts: 464 Credit: 56,639,936 RAC: 0 |
Yes, I had been monitoring your host since you started this test. I'd have to say this is an encouraging outcome so far, in that there doesn't seem to be a fundamental defect in the MT functionality. This makes me wonder if the lack of a 'plan_class' was deliberate in order to limit testing variables by forcing ST mode. One question I have is if the app runs in 'exclusive' mode on the cores allowed with the app_info, or does it share on cores with other tasks running like my 'unregulated' XPP-64 host does. That's something I can't see from my end. The other thing which came to mind is, and I think is a pretty safe thing to say as a general recommendation for this nBody beta run: All users wishing to help test out this new version of the nBody application should set their Computing Preferences to leave tasks in memory when suspended for the Host Venue they run MW under, as well as avoid restarting BOINC or Windows itself and/or shutting the machine down while nBody tasks are running as much as is practicable. There is no doubt in my mind now this is essential on Vista and higher Windows hosts to avoid needlessly trashing WU's due to exceeding the max error count, as well as wasting your hosts' time completing a task it should have gotten credit for, but won't due to the inevitable '374' error it will get if it tries a restart from checkpoint. Who knows, it might even help narrow things down on the Linux and Darwin fronts as well. On my front, I was rooting through my nBody task lists and came across a couple of wingmen who had BOINC 6x running on Vista and higher. One was W7 and one was W8. The part which made me unhappy about it was even though they seemed to have a pretty good success rate with nBody, they had at least one '374' each. Worse, I couldn't see an indication of a restart and/or resume from memory on those tasks. So the question occurred to me, does the app spit out the detail info line to stderr when it resumes from memory or not? |
|
Send message Joined: 4 Sep 12 Posts: 219 Credit: 456,474 RAC: 0 |
Yes, I had been monitoring your host since you started this test. I'd have to say this is an encouraging outcome so far, in that there doesn't seem to be a fundamental defect in the MT functionality. This makes me wonder if the lack of a 'plan_class' was deliberate in order to limit testing variables by forcing ST mode. I've set up an app_info similar to the AQUA one I posted as an example some time ago. I don't want to exclude CPU work for other projects entirely, and I have a fairly heavy pair of GPUs on this host, so I want to keep some CPU resources free to feed them. So my personal balance for this test run is: 3 x cores to run MW as MT (set by -nthreads 3) 3 x cores to run other single-CPU projects (kept free by <max_ncpus> 3 for MW) 2 cores free to support the GPUs. I've also set up an app_config.xml file (only available in BOINC v7.0.42 and up) to restrict NBody to a <max_concurrent> of 1 task - I don't want two tasks running at once and using all my active cores. (note that I'm using 'cores' in the common simplistic parlance for 'fraction of available CPU resources' - I haven't set affinity or anything silly like that, so OS housekeeping and other tasks can dip in and out as needed.) I'm hesitant to post the whole thing here, because on other projects I've seen people grab app_info wholesale without first developing the skills to adapt it where needed for their own needs and for changing project requirements - we're already overdue for v1.06 of the test app, anticipated by Jake Bauer over a week ago. But if anybody with experience of rolling their own wants to PM me and ask for a copy, feel free. (Alinator, your PM has been received already - it'll be on its way in a few minutes) |
|
Send message Joined: 7 Jun 08 Posts: 464 Credit: 56,639,936 RAC: 0 |
Got it, thanks. One item of business I should take care of now pertains to my hypothesis on MT behavior during this beta testing. Regarding BOINC 7x on Vista+ hosts, it turns out that when running in ST mode there is no observable CPU time above the expected 1/x percent. My previous conclusions were based on what I was seeing while not being able to fully explore all the relevant factors at that time. This isn't to say that Windows can't/doesn't override what OpenMP has requested it do with MT applications, only that in the case of this beta run any MT execution time is insignificant compared to the total CPU time used when running the default configuration. |
|
Send message Joined: 7 Jun 08 Posts: 464 Credit: 56,639,936 RAC: 0 |
Resource Exceeded Error on XPP-64, B/6.12.34 Host An interesting failure for this Task. Both my host and the first wingman faulted out on this task with what looks like a 'Caught Scribbling to the Disk' error during what I'm going to presume was an attempt to checkpoint progress or finish up and exit upon completion. |
|
Send message Joined: 4 Sep 12 Posts: 219 Credit: 456,474 RAC: 0 |
Resource Exceeded Error on XPP-64, B/6.12.34 Host You mean the "Exit status 196 (0xc4) Unknown error number"? That means that the admins haven't updated the web display code here since changeset 1f7ddbfe - it should use case 196: return "EXIT_DISK_LIMIT_EXCEEDED" (for discussion, see Status 'Cancelled by server' changed - that's another exit code in the same batch) |
|
Send message Joined: 7 Jun 08 Posts: 464 Credit: 56,639,936 RAC: 0 |
You mean the "Exit status 196 (0xc4) Unknown error number"? That was the code for the wingman, mine was a 177 ERR_RSC_LIMIT_EXCEEDED which was/is a BOINC error message IIRC. I was figuring the discrepancy in exit codes was due to mine having a tighter limit on disk usage than the wingman did, or something along those lines. In any event, the stderr info was for a disk usage error on both of them. The $64,000 question now is this just a bad WU or a 'legitimate' bug induced fault out. The reason I pointed it out was I noticed some Linux hosts had a bunch of error messages about problems writing to disk while trying to update the checkpoint file in their stderr reports. Thought this might be the Windows version of the same thing since it happened with about the same amount runtime for roughly similar host hardware. |
|
Send message Joined: 4 Sep 12 Posts: 219 Credit: 456,474 RAC: 0 |
Regarding BOINC 7x on Vista+ hosts, it turns out that when running in ST mode there is no observable CPU time above the expected 1/x percent. My previous conclusions were based on what I was seeing while not being able to fully explore all the relevant factors at that time. On the other hand, when the app is forced into true multi-threaded running with the app_info, the recorded CPU time rises so that the ratio of CPU to elapsed time is roughly proportional to the number of CPU cores used. I mentioned a batch of tasks with estimated 30-second run times when I put the corrected <flops> value into app_info. Their total elapsed time was indeed, near enough, 30 seconds: but I noticed that a couple started with an extended 'startup' phase (during which no progress %age was shown): then a very rapid (~2 second) rush to 100%: then an extended 'cleanup' phase. The reports for those tasks show CPU time very close to elapsed time, which perhaps suggests that multiple cores are only used during the central, progress-recording, phase of the app. Unsurprising, really, but it really means that MT is very little help for those very short tasks, and simply sucks resources away from applications running for other projects. The 24-hour estimate task, on the other hand, finished in ~50 minutes, but recorded roughly three times that much CPU time - a clear advantage for MT. But even with the correct <flops> entry, I'm still getting a vastly inflated estimate for runtime - and I'm worried by that. By the time the admins find their way onto the MT page of the BOINC manual, and deploy this app 'for real', I hope the cause for this estimation problem will have been tracked down and eradicated. Otherwise, Milkyway will gain a reputation of being very 'unneighbourly' towards other BOINC projects. The way BOINC clients schedule MT tasks is like this. The task takes its turn in the queue, and is scheduled according to debt/priority in the normal way - so it will start when another task finishes, or when a running task checkpoints after reaching its 'task switch interval'. But when an MT task starts, BOINC abruptly pre-empts any other tasks that might be running, without paying any respect to checkpointing or TSI, so that all threads can start in unison. That, by itself, can be unfriendly unless 'keep tasks in memory' is set. But if the initial estimates are as bad as we've seen recently, Milkyway tasks will be scheduled to run immediately in 'High Priority' as soon as the download completes. That will undoubtedly be interpreted by (multi-project) volunteers as a project decision, and I fear that the "you're taking over my computer" criticism will be directed at the project admins, rather than the 'boinc central' programmers who wrote the main server code. |

©2026 Astroinformatics Group