
AMD FirePro S9150
Message boards :
Number crunching :
AMD FirePro S9150
Message board moderation
Previous · 1 · 2 · 3 · 4 · 5 · Next
| Author | Message |
|---|---|
|
Send message Joined: 28 Sep 17 Posts: 19 Credit: 60,732,047 RAC: 0 |
perhaps the errors are caused by overheating if doing too many WUs. AMD specs for the S9150 require 20 cfm at 45 degree max inlet temps. |
 Joseph Stateson Joseph StatesonSend message Joined: 18 Nov 08 Posts: 291 Credit: 2,464,218,041 RAC: 8,845 |
perhaps the errors are caused by overheating if doing too many WUs. AMD specs for the S9150 require 20 cfm at 45 degree max inlet temps. System requirements: 20 CFM airflow cooling at 45° C maximum inlet temperature, Available PCI Express x16 (dual slot), 3.0 for optimal performance Power supply plus one 2x4 (8-pin) and one 2x3 (6-pin) AUX power connectors, 2GB system memory Yes, I saw that, but even in my garage it never gets that hot. The attic on a hot day probably hits that 114f or higher in the middle of the summer. My S9100 has only a single 8pin unlike the s9150 and less memory. I have ECC enabled and have never seen an error. There are no MW errors (invalids) when running one concurrent task at a time. The MW invalids increase exponsntially as more concurrent tasks are added. Currently it is in the garage due to the 20cfm (or higher) blower as it makes too much noise. gpu-z measured temp is 65c for the S9100 and slighly less for the Q9550s cpu as reported by tthrottle. It is running 3 WUs at a time and ratio of valid to invalid stays about 500:1 When I was running 10 concurrent tasks I was getting an 8:1 ratio and that test was run inside with A/C probably 75f way under 45c. |
|
Send message Joined: 28 Sep 17 Posts: 19 Credit: 60,732,047 RAC: 0 |
did you by chance notice how hot the VRMs were? |
|
Joseph Stateson Send message Joined: 18 Nov 08 Posts: 291 Credit: 2,464,218,041 RAC: 8,845 |
did you by chance notice how hot the VRMs were? Unfortunately, S9xxx information is not as complete as most HD7950. In addition to missing measurements, the clock frequency on my S9100 is not fixed at its maximum value like the S9000 or HD79xx series. It varies with load but it does jump to its minimum (300) with no load like the other AMD boards. Just does not stay at 800 like one would expect. Maybe this is by design. Note the s9000 (equivalent to HD7950) is locked at 900, its maximum. According to AMD docs, the 9100 supports OpenCL 2.1 but is being used at 1.2 according to the MW stdout report. My guess NM did not test their program against this board to optimize their code but I dont blame them as this is not a widely used board as it is designed for servers and has no video output. The S9000 does have video but not the 9100. [EDIT] While both HD79xx and S9000 are the same basic chip, I have given up trying to get them to co-exist on the same motherboard. 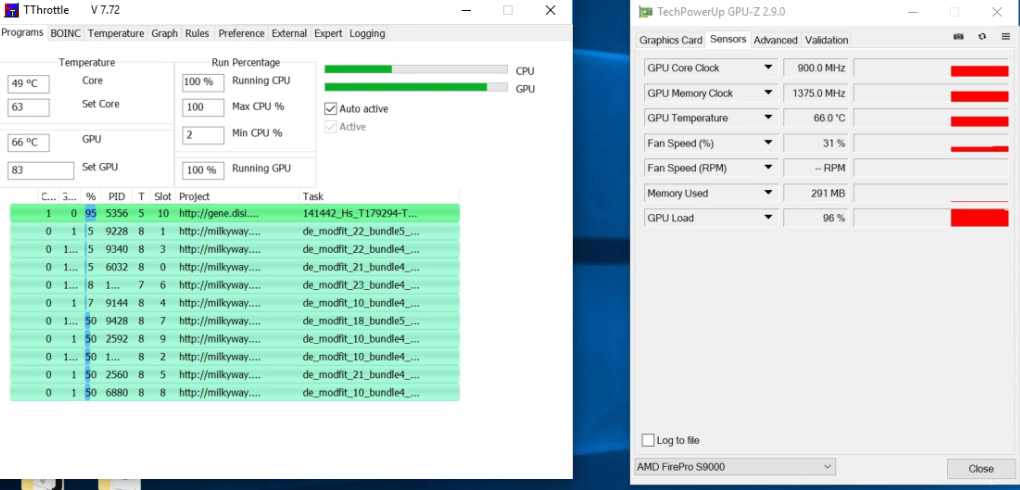 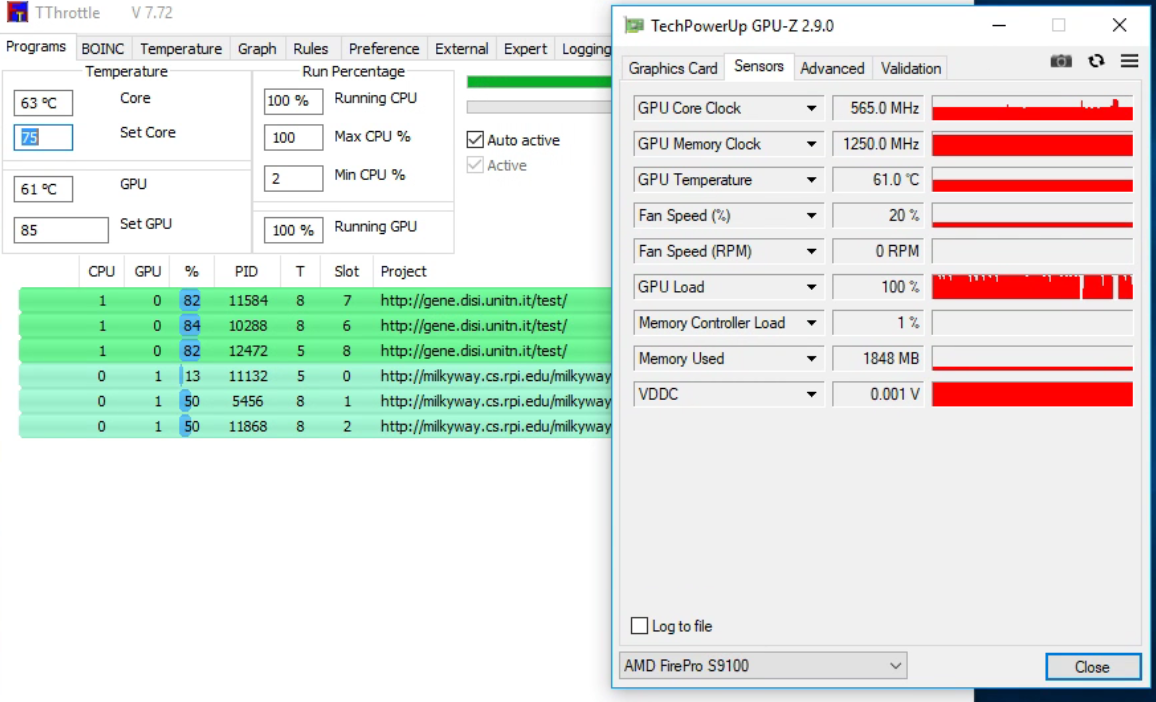 |
|
Send message Joined: 28 Sep 17 Posts: 19 Credit: 60,732,047 RAC: 0 |
On paper, s9150s and s9100 has so much potential with milkyway@home. hopefully you guys can figure out what causes the invalids. |
|
Joseph Stateson Send message Joined: 18 Nov 08 Posts: 291 Credit: 2,464,218,041 RAC: 8,845 |
On paper, s9150s and s9100 has so much potential with milkyway@home. hopefully you guys can figure out what causes the invalids. Found out a couple of things. (1) a new driver released 5-24 and (2) Found out how to better identify the S9xxx which is not being recognized properly (requires binary patch to exe). The following info can be observed by adding <cmdline>--verbose</cmdline> to the app_config file. Warp size: 64 ALU per CU: 5 Double extension: cl_khr_fp64 Double fraction: 1/5 --- --- Estimated AMD GPU GFLOP/s: 360 SP GFLOP/s, 72 DP FLOP/s Warning: Bizarrely low flops (72). Defaulting to 100 The above shows that MW assumes only 5 arithmetic logical units (ALU) are in a compute unit and assumes that 5 single precision operations can take place in the time it takes a single double precision to complete. In actuality, according to wiki, there are 64 ALUs and the S9150 can easily complete a double precision in only twice the time it takes to do a single 5070:2530 I looked at the source code and spotted a deficiency:"Hawaii" was missing from the list of AMD boards. S9xxx boards are hawaii series. 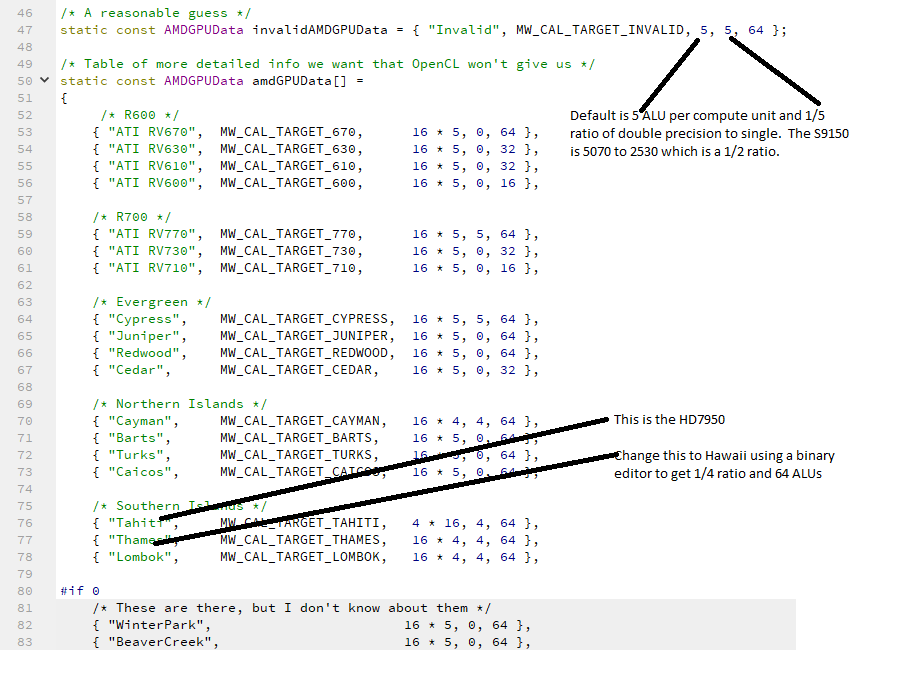 This can be fixed (at least for me) by changing "Thames" to"Hawaii" as I do not have a Thames graphics product. I used the free binary editor "neo" to make the change as shown here 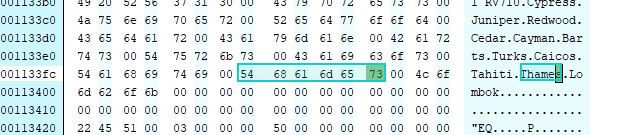 After making the change in that ati.exe I got the following results Warp size: 64 ALU per CU: 64 Double extension: cl_khr_fp64 Double fraction: 1/4 --- --- Estimated AMD GPU GFLOP/s: 4608 SP GFLOP/s, 1152 DP FLOP/s Using a target frequency of 1.0 Using a block size of 10240 with 55 blocks/chunk Anyway, after all this work, I still do not have TESLA performance, but it is running about %20 faster. I suspect there are other factors involved, but at least my S9100 is better identified. I am processing 4 WUs at a time on both S9100 and S9000. Each WU is bundled as either 4 or 5 units. When I compare performance improvement I have to make sure that i am comparing the same bundles. |
|
Send message Joined: 28 Sep 17 Posts: 19 Credit: 60,732,047 RAC: 0 |
Isn't FP32 to FP64 ratio 1/2? |
|
Joseph Stateson Send message Joined: 18 Nov 08 Posts: 291 Credit: 2,464,218,041 RAC: 8,845 |
Must I do everything? where the source code shows 16*4,4,64 that is 40,4,40 hex change the 4 to a 2 as shown here  and get the following 1/2 ratio
Device 'Hawaii' (Advanced Micro Devices, Inc.:0x1002) (CL_DEVICE_TYPE_GPU)
Board: AMD FirePro S9100
Driver version: 2527.9
Version: OpenCL 1.2 AMD-APP (2527.9)
Compute capability: 0.0
Max compute units: 40
Clock frequency: 900 Mhz
Global mem size: 3221225472
Local mem size: 32768
Max const buf size: 3221225472
Double extension: cl_khr_fp64
Build log:
--------------------------------------------------------------------------------
C:\Users\JSTATE~1\AppData\Local\Temp\\OCL7972T4.cl:183:72: warning: unknown attribute 'max_constant_size' ignored
__constant real* _ap_consts __attribute__((max_constant_size(18 * sizeof(real)))),
^
C:\Users\JSTATE~1\AppData\Local\Temp\\OCL7972T4.cl:185:62: warning: unknown attribute 'max_constant_size' ignored
__constant SC* sc __attribute__((max_constant_size(NSTREAM * sizeof(SC)))),
^
C:\Users\JSTATE~1\AppData\Local\Temp\\OCL7972T4.cl:186:67: warning: unknown attribute 'max_constant_size' ignored
__constant real* sg_dx __attribute__((max_constant_size(256 * sizeof(real)))),
^
3 warnings generated.
--------------------------------------------------------------------------------
Estimated AMD GPU GFLOP/s: 4608 SP GFLOP/s, 2304 DP FLOP/s
Using a target frequency of 60.0
|
|
Send message Joined: 28 Sep 17 Posts: 19 Credit: 60,732,047 RAC: 0 |
Yes =) I'm trying to learn source codes, but I'm a noob compared to you. You're on to something! Will you test it and see if you get any errors? Your work rate is probably almost double compared to the original setting. Definitely a Kepler Titan killer right here. |
|
Send message Joined: 10 Dec 17 Posts: 47 Credit: 695,662,962 RAC: 0 |
Nice investigative work Beemer. I will need to look into this more and likely attempt the same patch you have just discovered. |
|
Send message Joined: 13 Jun 09 Posts: 24 Credit: 160,141,270 RAC: 179,639 |
Couldn't the project team fix this in the source code? Seems like you did all the work for them |
|
Send message Joined: 10 Mar 13 Posts: 9 Credit: 523,622,956 RAC: 0 |
Has anyone tried to PM the project admin or developers about this? Thanks to BeemerBike making the above changes to the binary as described above is easy enough, but I assume the binary will be overwritten next update. |
|
Send message Joined: 13 Jun 09 Posts: 24 Credit: 160,141,270 RAC: 179,639 |
I just did, will post back if there is some news. |
|
Send message Joined: 25 Feb 13 Posts: 580 Credit: 94,200,158 RAC: 0 |
Hey Everyone, I just got pointed over to this thread. Wow you guys did a deep dive into this issue. Thank you for that. If someone already has the fix for this coded up, you can make a pull request on the source on Github. If you do that, I will do some internal testing on the new code and push it out to users sometime next week. If you do not want to do that, I will read through this thread and try to implement the fix myself. Thank you all for all of your help, Jake |
|
Send message Joined: 4 Mar 18 Posts: 23 Credit: 269,259,098 RAC: 42,488 |
Hi everyone, I created a PR on github regarding to this issue. Thanks BeemerBiker! https://github.com/Milkyway-at-home/milkywayathome_client/pull/67 CC: Jake Weiss |
|
Send message Joined: 4 Mar 18 Posts: 23 Credit: 269,259,098 RAC: 42,488 |
FYI, here is a snippet of the output from the newly merged code from github, sample from 82465335
Platform 0 information:
Name: AMD Accelerated Parallel Processing
Version: OpenCL 2.1 AMD-APP (2671.3)
Vendor: Advanced Micro Devices, Inc.
Extensions: cl_khr_icd cl_amd_event_callback cl_amd_offline_devices
Profile: FULL_PROFILE
Using device 0 on platform 0
Found 1 CL device
Device 'Hawaii' (Advanced Micro Devices, Inc.:0x1002) (CL_DEVICE_TYPE_GPU)
Board: AMD Radeon FirePro W9100
Driver version: 2671.3
Version: OpenCL 1.2 AMD-APP (2671.3)
Compute capability: 0.0
Max compute units: 44
Clock frequency: 900 Mhz
Global mem size: 16790622208
Local mem size: 32768
Max const buf size: 4244635648
Double extension: cl_khr_fp64
Build log:
--------------------------------------------------------------------------------
/tmp/OCL16522T3.cl:183:72: warning: unknown attribute 'max_constant_size' ignored
__constant real* _ap_consts __attribute__((max_constant_size(18 * sizeof(real)))),
^
/tmp/OCL16522T3.cl:185:62: warning: unknown attribute 'max_constant_size' ignored
__constant SC* sc __attribute__((max_constant_size(NSTREAM * sizeof(SC)))),
^
/tmp/OCL16522T3.cl:186:67: warning: unknown attribute 'max_constant_size' ignored
__constant real* sg_dx __attribute__((max_constant_size(256 * sizeof(real)))),
^
3 warnings generated.
--------------------------------------------------------------------------------
Estimated AMD GPU GFLOP/s: 5069 SP GFLOP/s, 2534 DP FLOP/s
Using a target frequency of 60.0
Using a block size of 11264 with 49 blocks/chunk
Using clWaitForEvents() for polling (mode -1)
Range: { nu_steps = 320, mu_steps = 800, r_steps = 700 }
Iteration area: 560000
Chunk estimate: 1
Num chunks: 2
Chunk size: 551936
Added area: 543872
Effective area: 1103872
Initial wait: 0 ms
Integration time: 15.889514 s. Average time per iteration = 49.654731 ms
Integral 0 time = 16.441450 s
Running likelihood with 84044 stars
Likelihood time = 1.241216 s
Build steps: mkdir /tmp/MW /tmp/MW/build cd /tmp git clone https://github.com/Milkyway-at-home/milkywayathome_client cd milkywayathome_client git submodule init git submodule update --recursive cd ../build cmake -DBUILD_32=OFF -DSEPARATION=ON -DNBODY=OFF -DSEPARATION_OPENCL=ON \ -DOPENCL_LIBRARIES=/opt/amdgpu-pro/lib/x86_64-linux-gnu/libOpenCL.so.1 \ -DOPENCL_INCLUDE_DIRS=/opt/amdgpu-pro/include/CL/ ../milkywayathome_client make |
|
Send message Joined: 13 Oct 16 Posts: 112 Credit: 1,174,293,644 RAC: 0 |
So is the MilkyWay code fixed to include "Hawaii" based GPUs now? Or is this still a manual fix? Thanks, blue |
|
Send message Joined: 4 Mar 18 Posts: 23 Credit: 269,259,098 RAC: 42,488 |
So is the MilkyWay code fixed to include "Hawaii" based GPUs now? Or is this still a manual fix? It's in the public github source repo but not in the public binary release yet. I compile and overwrite the current installed binary with this latest one. |
|
Joseph Stateson Send message Joined: 18 Nov 08 Posts: 291 Credit: 2,464,218,041 RAC: 8,845 |
I never got cmake to work but will look at this again. As you got it working then my guess that not all code was available was wrong. However, the problem I see with the 9xx0 is not the failure to identify the board but the exponential increase in invalids that occur when the number of concurrent tasks increase. Looking for "results" shows nothing. Unlike setiathome "result" errors are not discernable, at least to me. On seti I can compare my results to those of the wingmen and on the few occasions I have an error, clearly the computed results of the 2 wingmen match, and are different than my computed result. I am guessing that the invalid is caused by some scheduling failure in the opencl. There are actually 5 tasks for each work unit, shown (for example in task result...) <number_WUs> 5 </number_WUs> <number_params_per_WU> 20 </number_params_per_WU
<app_version> <app_name>milkyway</app_name> <plan_class>opencl_ati_101</plan_class> <avg_ncpus>0.25</avg_ncpus> <ngpus>0.25</ngpus> <cmdline>--non-responsive --verbose --gpu-target-frequency 1 --gpu-polling-mode -1 --gpu-wait-factor 0 --process-priority 4 --gpu-disable-checkpointing</cmdline> </app_version>
|
|
Send message Joined: 4 Mar 18 Posts: 23 Credit: 269,259,098 RAC: 42,488 |
@BeemerBiker: There is thread somewhere about Nvidia Titan V running MH. In that thread, the author mentions about each WU uses about 1.5GB of VRAM. So you can run about 6 WUs on a S9100 (12GB) or 8-10 WUs on S9150 (16GB). As for compiling, here is roughly how I do it in Linux: https://gist.github.com/neofob/8a73e2f44787541c11c0445763953950 |

©2026 Astroinformatics Group